
Imagine converting any text into lifelike speech within seconds—AI makes it effortless!
Text-to-Speech (TTS) AI is becoming increasingly popular as it transforms text into realistic, human-like speech within seconds.
From businesses enhancing customer interactions to individuals using it for audiobooks and accessibility, its applications are expanding.
As AI technology improves, TTS is evolving to sound more natural, making it a valuable tool across various industries.
What is Text to Speech AI?
Text-to-Speech (TTS) AI is an advanced technology that transforms written text into spoken words using artificial intelligence. It leverages deep learning, natural language processing (NLP), and speech synthesis to produce clear, natural-sounding voices.
Unlike older TTS systems, AI-powered TTS can adapt to context, adjust tone, and replicate human speech patterns, making interactions feel more lifelike.
This technology is widely applied in virtual assistants, accessibility solutions, customer service, and content creation, enhancing voice-based communication across various industries. As AI evolves, TTS continues to improve, offering more realistic and personalized speech experiences.
How TTS AI Differs from Traditional Text-to-Speech Software
Text-to-Speech (TTS) AI represents a significant advancement over traditional TTS technologies.
While both aim to convert text into spoken language, there are several critical differences in how they function and the quality of the output.
Here’s a breakdown of how TTS AI stands apart from its traditional counterparts:
1. Sound Quality and Technology
- Traditional TTS Software: Traditional TTS systems often rely on concatenative synthesis, which pieces together segments of pre-recorded human voices to form complete sentences. While this method provides intelligible speech, the result can sound robotic and lack the fluidity and variation found in human speech. The speech output can feel rigid and unnatural, especially in longer conversations.
- TTS AI: TTS AI uses deep learning and neural networks (specifically Neural Text-to-Speech, NTTS) to produce speech that closely mirrors natural human voices. AI systems are able to simulate human inflection, tone, and rhythm, which makes the speech more engaging and lifelike. AI can adjust to different emotions and contexts, creating a more dynamic and realistic experience.
2. Adaptability and Flexibility
- Traditional TTS Software: Traditional systems are typically limited in their ability to adjust voice characteristics such as pitch, tone, or speed. These systems offer only basic control over voice output and struggle with complex language features, like varying emotional tones or accents, resulting in monotonous speech.
- TTS AI: AI-driven TTS systems are far more adaptable, offering real-time adjustments in pitch, tone, speed, and emotion based on the context. Whether the task requires a formal or casual tone, or even conveying excitement or sadness, TTS AI can modify its voice accordingly. It also allows for more personalized voices, enabling users to select accents, languages, or specific voice styles suited to their needs.
3. Understanding Context
- Traditional TTS Software: Traditional systems often lack the ability to fully grasp the meaning behind the text they’re reading. As a result, they tend to mispronounce homophones, fail to apply appropriate pauses, and produce speech that doesn’t capture the nuances of the language.
- TTS AI: TTS AI incorporates natural language processing (NLP), allowing it to analyze the structure and meaning of sentences. This enables the system to correctly interpret and pronounce words based on their context, providing more accurate speech patterns. AI can identify word emphasis, adjust for proper pauses, and reflect the emotional tone embedded in the text, making the speech sound more fluid and human-like.
4. Real-Time Learning and Improvement
- Traditional TTS Software: Traditional systems are generally static, operating based on predefined voice samples and algorithms. They cannot evolve unless manually updated or reprogrammed, meaning their performance and quality remain consistent, but rarely improve.
- TTS AI: AI-powered TTS systems learn from vast datasets, improving over time. As they process more data, they become better at recognizing language nuances, regional accents, and conversational cues. With the help of machine learning, these systems continuously refine their performance, resulting in more natural and accurate voice outputs as they interact with users.
5. Scalability and Language Support
- Traditional TTS Software: Traditional TTS systems typically require large databases of voice recordings for different languages or accents. Expanding these systems to support new languages or dialects can be a time-consuming and resource-intensive process.
- TTS AI: AI-based TTS systems offer superior scalability. By utilizing deep learning models, AI systems can be trained on a wide variety of languages, accents, and regional variations, often with minimal additional resources. This makes AI TTS more flexible and easier to deploy across different languages and use cases, without compromising on quality.
6. Range of Applications
- Traditional TTS Software: Traditional TTS systems are generally suitable for basic use cases, such as reading static text for educational purposes, screen readers for the visually impaired, or simple automated voice responses. They are not well-suited for more dynamic interactions or complex voice tasks.
- TTS AI: AI-powered TTS has a far broader scope of applications. It is used in virtual assistants (e.g., Siri, Alexa), customer service chatbots, real-time translation, audiobook narration, and interactive voice interfaces. AI can handle ongoing, dynamic conversations, making it a key tool for industries requiring personalized or context-driven voice interactions.
7. Cost and Resource Efficiency
- Traditional TTS Software: Traditional systems, especially those relying on concatenative synthesis, often require large amounts of storage for voice samples, which can make them more costly to maintain and scale. These systems also require more manual input to update and expand voice models.
- TTS AI: AI-driven TTS solutions are typically more cost-efficient in the long run. As AI models generate voice dynamically, they require fewer resources for storage and are more adaptable to new use cases. Over time, as machine learning models become more efficient, the costs of implementation and maintenance decrease, making TTS AI more accessible and scalable for businesses.
How does Text to Speech AI work?
1. Text Analysis
The process starts with breaking down the input text to ensure accurate pronunciation and natural flow. Key steps in this phase include:
- Sentence Structure Parsing: The AI evaluates punctuation, sentence length, and grammatical elements to determine how to approach the text.
- Contextual Understanding: For words with multiple meanings or pronunciations, the system uses surrounding words and context to decide on the correct pronunciation.
- Handling Numbers & Abbreviations: The AI automatically expands abbreviations (e.g., “Dr.” to “Doctor”) and converts numbers into spoken words (e.g., “2025” to “two thousand twenty-five”).
2. Natural Language Processing (NLP)
NLP plays a vital role in understanding the intricacies of human speech. This step ensures that the AI can generate speech that sounds fluid and natural by:
- Phoneme Breakdown: Words are converted into phonemes, the basic units of sound, to ensure precise pronunciation.
- Linguistic Rule Application: Language-specific rules guide correct stress patterns and rhythm, enhancing intelligibility and flow.
- Prosody Modulation: The AI adjusts elements such as pitch, rhythm, and emphasis to create expressive speech that sounds more human-like.
3. Speech Synthesis Techniques
After the text is processed, the AI synthesizes speech using one of several methods:
- Concatenative Synthesis: This approach uses pre-recorded voice segments that are stitched together to form words and sentences. While it’s clear and natural, it lacks flexibility.
- Parametric Synthesis: This method creates speech by modeling the human vocal system, allowing for more flexibility but often sounding less natural.
- Neural Text-to-Speech (NTTS): The most cutting-edge method, NTTS uses deep neural networks to generate fluid and emotionally nuanced speech, resulting in voices that are nearly indistinguishable from human speakers. This is the approach used by most modern virtual assistants, like Siri and Alexa.
4. Customization & Adaptive Response
Many TTS systems offer users the ability to customize their experience by adjusting:
- Voice Options: Selecting different voices, accents, or languages for a personalized touch.
- Tone & Emotion: Adjusting the tone of voice to reflect specific emotions like excitement, calmness, or seriousness.
- Speech Speed & Pitch: Tailoring the pace and pitch of speech to individual preferences or specific use cases, such as faster speech for brief information or slower speech for clarity.
The latest TTS systems can also adapt in real-time to conversational contexts, shifting tone or inflection based on the user’s emotional state or conversational flow.
5. Output & Real-World Uses
Once the text has been converted to speech, it can be delivered immediately or saved as an audio file. The applications of TTS AI are broad, including:
- Accessibility Tools: Providing spoken text for visually impaired individuals, such as in screen readers.
- Virtual Assistants: Powering voice interactions in devices like Amazon’s Alexa, Apple’s Siri, and Google Assistant.
- Customer Service Automation: Enhancing automated phone systems or chatbots for better, human-like interactions.
- Content Creation: Transforming written material like articles, books, and videos into spoken words.
- Language Learning: Offering pronunciation support and helping learners practice new languages.
Benefits of Using Text to Speech AI
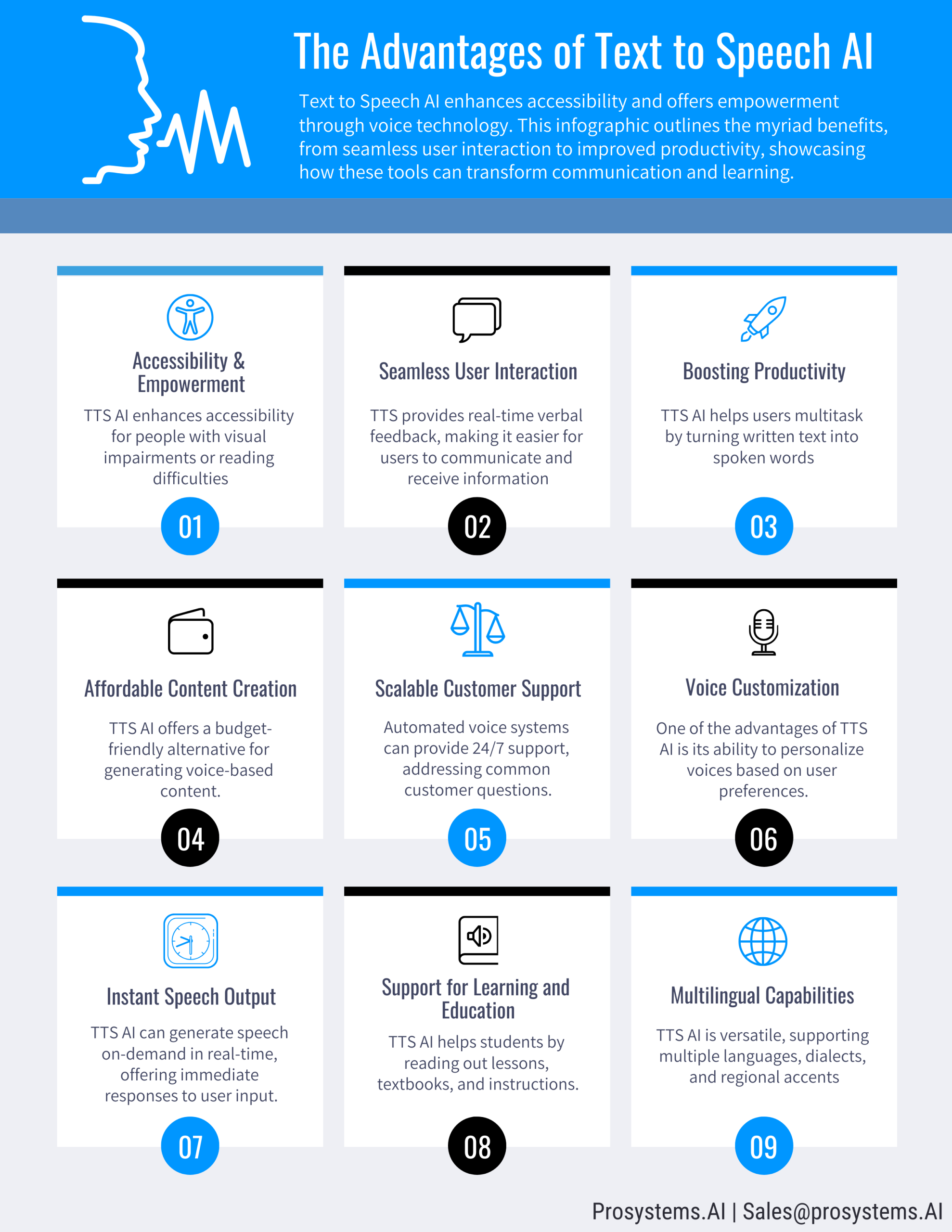
1. Accessibility and Empowerment
TTS AI enhances accessibility for people with visual impairments or reading difficulties. It enables users to engage with digital content by converting text into speech, making websites, books, and educational resources accessible to everyone. This empowers people with disabilities, ensuring they can consume content without barriers.
2. Seamless User Interaction
TTS AI creates smoother, more interactive user experiences. Virtual assistants like Google Assistant, Alexa, and Siri use TTS to provide real-time verbal feedback, making it easier for users to communicate and receive information. This creates a more dynamic, hands-free interaction, perfect for tasks that require quick, auditory responses.
3. Boosting Productivity
TTS AI helps users multitask by turning written text into spoken words. Busy professionals can listen to articles, emails, or reports while performing other activities, such as driving or exercising. This boosts productivity, as it allows users to absorb information without needing to focus on a screen.
4. Cost-Effective Content Creation
TTS AI offers a budget-friendly alternative for generating voice-based content, such as audiobooks or voiceovers, without needing a voice actor. With customizable voice styles, accents, and tones, businesses can save on production costs while still creating high-quality content.
5. Scalable Customer Support
By integrating TTS AI into customer service operations, businesses can handle a large volume of inquiries efficiently. Automated voice systems can provide 24/7 support, addressing common customer questions and issues without human intervention. This scalability enhances customer satisfaction while reducing operational costs.
6. Voice Customization
One of the advantages of TTS AI is its ability to personalize voices based on user preferences. From adjusting the tone to selecting accents or emotional expressions, businesses can tailor TTS voices to align with their brand identity, creating a more engaging and human-like interaction.
7. Instant Speech Output
TTS AI can generate speech on-demand in real-time, offering immediate responses to user input. This is crucial in applications like live translations, virtual assistants, and interactive voice interfaces, where speed and accuracy are essential for effective communication.
8. Support for Learning and Education
In educational environments, TTS AI helps students by reading out lessons, textbooks, and instructions. It also aids in language learning, pronunciation, and comprehension. By offering a model of proper speech patterns, it enhances both language skills and engagement for learners of all ages.
9. Multilingual Capabilities
TTS AI is versatile, supporting multiple languages, dialects, and regional accents. This makes it an excellent tool for businesses aiming to provide global customer support, allowing them to communicate with audiences in their native languages and improve overall user experience.
10. Promoting Mental Well-Being
TTS AI can also be used in wellness applications to support mental health. Calming, soothing voice outputs can guide users through relaxation exercises, meditation, or stress-relief activities. This can contribute to emotional well-being by offering personalized, comforting interactions
How to Choose the Right AI Text to Speech Tool

The primary factor when selecting a TTS tool is the quality of the generated voice. Opt for tools that leverage advanced neural networks or deep learning models, as these tend to produce voices that sound more human-like and natural.
Ensure you test out the voices to confirm they have natural rhythm, tone, and intonation, as poorly generated speech can detract from user experience.
2. Language and Accent Options
Different TTS tools support various languages and accents, so it’s essential to choose one that fits your target audience.
If you’re serving an international customer base, look for a tool that supports multiple languages and regional accents. This flexibility is especially important for global businesses or applications requiring diverse linguistic support.
3. Customization Features
Customization is another important factor. Some TTS tools allow you to adjust pitch, speed, and intonation, giving you control over the output voice.
If your project requires a distinctive voice for branding or personalization, ensure the tool offers advanced features such as voice cloning or custom voice creation to match your specifications.
4. Compatibility and Integration
Consider how well the TTS tool integrates with your existing systems. Whether you’re using it for a website, app, or customer support system, check if the tool offers easy integration through APIs or built-in plugins. Compatibility with your platform is vital for ensuring smooth implementation and use.
5. Usability and Interface
The ease of use of the TTS tool can greatly affect how quickly you can deploy and use it. Choose a tool with a simple and intuitive interface, particularly if you don’t have technical expertise.
Some tools offer easy-to-navigate dashboards, while others may be more complex and require specialized knowledge to configure advanced features.
6. Pricing and Value for Money
Pricing structures can vary significantly across TTS providers. Some tools charge based on usage, such as per word or character, while others offer monthly subscriptions.
When evaluating the price, make sure it aligns with the value offered by the tool, considering both its features and the quality of the speech it produces. If you’re just starting, a pay-as-you-go option may be ideal, while larger businesses might benefit from a subscription with more extensive features.
7. Performance and Speed
The speed at which a TTS tool processes and converts text to speech is crucial for real-time applications. If you’re using TTS for customer support or virtual assistants, you’ll need a tool that provides quick and accurate responses without delays. Test the tool to ensure it meets your real-time processing requirements.
8. Voice Variety and Flexibility
Look for a TTS tool that provides a variety of voices to choose from, including different genders, ages, and personalities. This variety allows for greater flexibility in choosing the right voice for your brand or project.
Some platforms even let you adjust emotions or tones for more dynamic and engaging speech, making interactions feel more human.
9. Accessibility Feature
For applications focused on accessibility, choose a TTS tool that supports features like screen readers, text highlighting, or easy-to-adjust speech settings (e.g., speed, pitch).
These features ensure that users with disabilities have a better experience and can easily navigate content.
10. Security and Data Privacy
If you’re processing sensitive data, it’s critical to select a TTS tool that follows strict security protocols. Ensure that the platform complies with relevant data protection laws (such as GDPR or HIPAA) to safeguard any personal or confidential information.
Always review the tool’s privacy policies and data handling practices before integrating it into your system.
11. Support and Documentation
Choose a TTS tool with strong customer support and comprehensive documentation. This is especially important for troubleshooting or when you need assistance with implementation.
Having access to online resources, tutorials, and responsive support channels will make it easier to get help when needed.
Top Free AI Text-to-Speech Tools
1. Google Cloud Text-to-Speech
Google’s Cloud Text-to-Speech service uses WaveNet technology to deliver exceptionally realistic voices. It supports over 180 voices across multiple languages and accents, offering a high degree of flexibility for diverse applications.
The free tier provides up to 4 million characters per month, ideal for developers and users looking to experiment with TTS in their projects.
Key Features:
- WaveNet-based voices for lifelike speech
- Wide language and accent support
- Customizable settings for pitch, speed, and tone
- Free tier: 4 million characters per month
2. Amazon Polly
Amazon Polly is another powerful TTS service that uses neural networks to create natural-sounding voices. It supports a variety of languages, including regional accents, and allows users to fine-tune speech using SSML (Speech Synthesis Markup Language).
The free tier grants 5 million characters per month for the first year, making it an excellent choice for businesses and developers.
Key Features:
- High-quality neural voices
- Customizable speech via SSML
- Broad language support
- Free tier: 5 million characters per month (first 12 months)
3. ResponsiveVoice
ResponsiveVoice is a straightforward tool that provides simple integration into websites and apps. It features a variety of voices and languages, and while the free version offers basic capabilities, it still delivers solid TTS output for smaller projects. This tool is particularly useful for quickly adding speech functionality to websites without complex setup.
Key Features:
- Easy integration for web-based applications
- Multiple languages and voices available
- Free version with basic features
- No installation required for use
4. Balabolka
Balabolka is an open-source TTS tool that offers offline functionality, making it a great option for users who prefer not to rely on an internet connection. It supports multiple file formats like TXT, DOCX, and HTML and comes with various voices that can be adjusted for pitch, speed, and tone. While it lacks the advanced AI features of cloud-based services, it’s a solid, free solution for offline TTS needs.
Key Features:
- Offline usage without internet connection
- Supports a variety of file formats
- Customizable voice settings
- Free and open-source
5. Natural Reader
Natural Reader offers both a web-based and desktop TTS solution, with a variety of voices and languages available. The free version includes core features that are ideal for personal use, such as listening to articles or documents. The intuitive interface makes it easy for users of all experience levels to quickly start converting text into speech.
Key Features:
- Web and desktop versions available
- Variety of voices and languages
- User-friendly interface
- Free version with essential features
6. TTSReader
TTSReader is a simple, free web-based tool designed for personal use. It offers clear and natural-sounding voices and can read content directly from web pages or documents.
The tool also features automatic scrolling while reading, making it ideal for listening to e-books or articles. With no installation required, it’s a convenient, lightweight solution for everyday TTS needs.
Key Features:
- Browser-based tool with no installation needed
- Multiple language options
- Automatic text scrolling during reading
- Simple and intuitive user interface
7. iSpeech
iSpeech offers both free online and premium TTS services. The free version provides high-quality voices and allows users to convert text into speech for personal projects. It’s a straightforward tool, perfect for casual use, but with limited advanced features compared to paid plans.
Key Features:
- High-quality, natural-sounding voices
- Easy-to-use online tool
- Free version with basic functionalities
- Quick text-to-speech conversion
8. Voice Dream Reader (Free Version)
Voice Dream Reader is a versatile tool that allows users to listen to text from various file formats such as PDFs, DOCX, and web pages.
While the free version has limited features, it’s still a great option for those looking to turn documents into audio for personal use. It also supports customization for speech speed and pitch, ensuring an optimized listening experience.
Key Features:
- Supports multiple file formats (PDF, DOCX, web pages)
- Customizable voice settings
- Free version with essential features
- Focus on accessibility
Q&As
Q: Are Text to Voice and Text to Speech the same thing?
A: Yes & No. Text-to-voice and text-to-speech are often used interchangeably, but they can refer to slightly different concepts depending on the context.`
Q: Can Text-to-Speech AI generate voices that sound human-like?
A: Absolutely! Advanced TTS AI systems utilize deep learning algorithms and neural networks, such as Google’s WaveNet or Amazon Polly, to produce voices that closely resemble human speech. These models can replicate natural speech patterns, including tone, emotion, and regional accents, making the output far more lifelike compared to traditional robotic voices.
Q: What are the primary applications for Text-to-Speech AI?
A: Text-to-Speech AI is commonly used in:
- Virtual assistants (e.g., Siri, Alexa)
- Accessibility tools for individuals with visual impairments
- Content creation, including audiobooks, podcasts, and automated voiceovers
- Language learning applications
- Customer service, utilizing voicebots for automation
- Call center automation for efficiently handling customer inquiries
Q: How can businesses leverage Text-to-Voice AI?
A: Businesses can harness Text-to-Voice AI for:
- Improving customer service with intelligent voice assistants
- Automating content distribution, such as news updates and promotional content
- Enhancing user engagement by creating dynamic, interactive voice experiences
- Personalizing communication by tailoring responses to users’ needs in real-time
Q: What sets “neural” voices apart from “standard” Text-to-Speech voices?
A: Neural voices are generated by cutting-edge AI models that produce speech with far greater naturalness, incorporating realistic pacing, tone, and emotion. In contrast, standard voices are more mechanical and lack the fluidity and expressiveness of neural voices. As a result, neural voices tend to sound more authentic and are favored in modern TTS systems.
Q: How do Text-to-Speech AI tools manage various languages and accents?
A: Modern TTS AI tools can support an extensive range of languages and accents by using specialized models trained on diverse data sets. This allows them to accurately pronounce words and adapt to various regional dialects, ensuring culturally relevant and precise speech output across different languages.
Q: Is real-time speech generation possible with Text-to-Speech AI?
A: Yes, many TTS AI solutions are capable of real-time speech synthesis, making them perfect for applications like interactive voice assistants, live translation services, and real-time customer support. These systems can process written text and generate voice responses almost instantly.
Leave a Reply